目录
知识点
2,dict,enumerate,lambda,join
3,Counter,lambda
4,Counter,items,哈希表
5,items,append
6,items,哈希表,集合
7,items,哈希表,bool
8,切片 [:k]
9,哈希表,enumerate
791.自定义字符串排序
给定两个字符串 order 和 s 。order 的所有字母都是 唯一 的,并且以前按照一些自定义的顺序排序。
对 s 的字符进行置换,使其与排序的 order 相匹配。更具体地说,如果在 order 中的字符 x 出现字符 y 之前,那么在排列后的字符串中, x 也应该出现在 y 之前。
返回 满足这个性质的 s 的任意一种排列 。

思路:
用for循环依次记录字符串order中元素与顺序,用defaultdict储存,将字符串s按该顺序排序。
题解:
class Solution:
def customSortString(self, order: str, s: str) -> str:
val = defaultdict(int)
for i, ch in enumerate(order):
val[ch] = i + 1
return "".join(sorted(s, key=lambda ch: val[ch]))
# (来源力扣)分析:
for i, ch in enumerate(order):使用 enumerate 函数遍历 order 字符串中的每个字符和对应的索引。
enumerate()将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
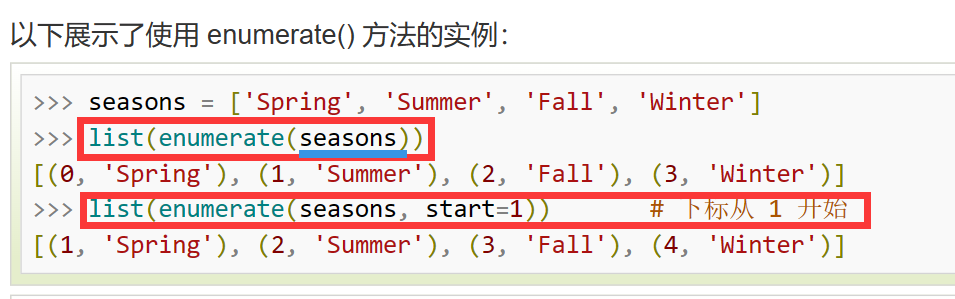
val[ch] = i + 1:
将字典 val 中键 ch 的值设置为 i + 1。
sorted(s, key=lambda ch: val[ch]):
使用 sorted 函数来对字符串 s 进行排序。lambda ch: val[ch] 接受字符 ch 作为输入,并返回其在字典 val 中对应的值(val[ch])。这样,sorted()函数会按照 val 字典中字符对应的值的顺序排序。
例如,假设 val 字典为 {'a': 2, 'b': 1, 'c': 3},而 s 为 "cba"。根据这个 key 函数,sorted(s, key=lambda ch: val[ch]) 将返回一个经过排序的字符串 "bac",因为在 val 字典中,'b' 对应的值是1,'a' 对应的值是2,'c' 对应的值是3。
注:
在Python的dict或defaultdict中,当尝试访问一个不存在的键时,会返回一个默认值。对于普通的dict类型,如果访问一个不存在的键,则会抛出KeyError异常。而对于defaultdict类型,如果访问一个不存在的键,则会使用该字典预先指定的默认值。
这里我们通过defaultdict(int)创建了一个defaultdict类型的字典。这里的int表示默认值为0,即当访问一个不存在的键时,默认返回0。
所以,在遍历'order'字符串并为每个字符设置权值时,对于没有出现过的字符,默认权值是0。在排序时,这些权值为0的字符会被放在所有出现过的字符之后。
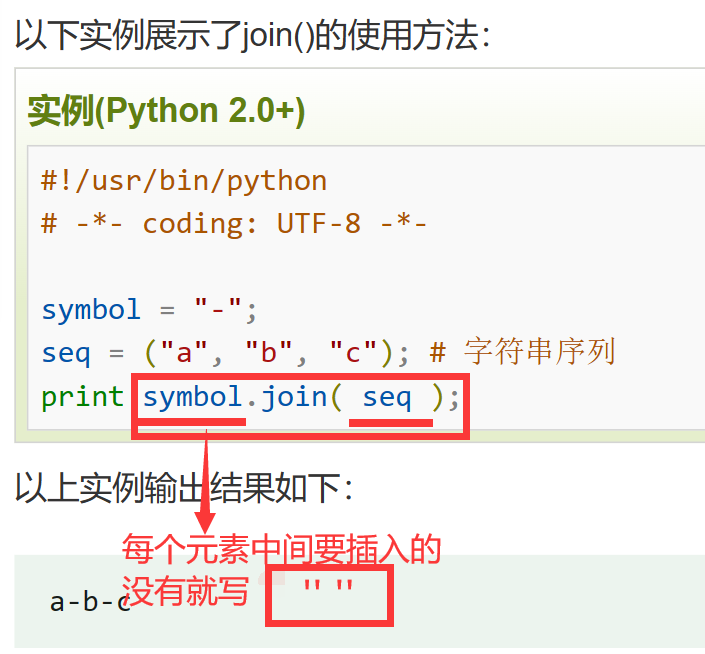
join() 将序列中的元素以指定的字符连接生成一个新的字符串。
1636. 按照频率将数组升序排序
https://leetcode.cn/problems/sort-array-by-increasing-frequency/
给你一个整数数组 nums ,请你将数组按照每个值的频率 升序 排序。如果有多个值的频率相同,请你按照数值本身将它们 降序 排序。
请你返回排序后的数组。

思路:
先算nums频率用Counter()存进字典,用lambda按频率排序,频率相同时再按大小排序(反序)
题解:
class Solution:
def frequencySort(self, nums: List[int]) -> List[int]:
cnt = Counter(nums)
nums.sort(key=lambda x: (cnt[x], -x))
return nums
# (来源力扣)分析:
cnt = Counter(nums):
(区分)count():统计列表或字符串中某个元素出现的次数。list.count(element)
Counter():需要先导入 collections 模块(from collections import Counter)。Counter 类可以接受一个可迭代对象作为参数,例如一个列表或字符串。它会遍历可迭代对象中的元素,并统计各个元素出现的次数,最终返回一个字典,其中元素作为键,出现次数作为值。
nums.sort(key=lambda x: (cnt[x], -x)):
对列表 nums 进行排序,先按照每个元素在计数器 cnt 中的出现次数从小到大进行排序,如果出现次数相同,则按照元素的值从大到小进行排序。
注意括号。
用dict实现cnt:
剑指 Offer II 004. 只出现一次的数字
https://leetcode.cn/problems/WGki4K/description/
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。

思路:
找出现频率1的数字。用Counter()记录数字(key)与频率(value),用for遍历字典,找到并返回value==1的值。
题解:
class Solution:
def singleNumber(self, nums: List[int]) -> int:
cnt = Counter(nums)
for key, value in cnt.items():
if value == 1:
return key分析:
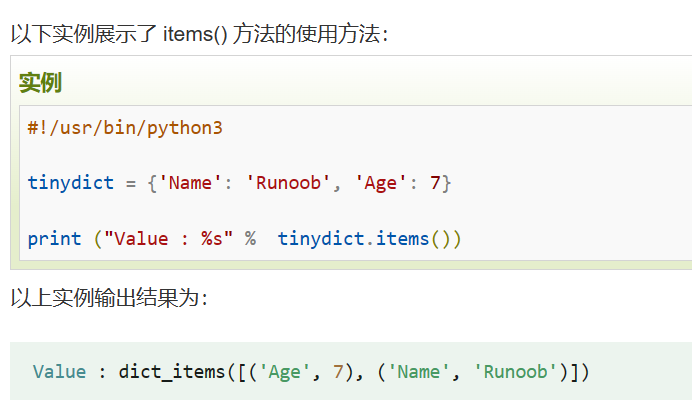
for key, value in cnt.items():
dict.items()返回一个包含字典的键值对元组的列表,可以使用for循环来遍历这个列表。
哈希表解法:
class Solution:
def singleNumber(self, nums: List[int]) -> int:
freq = collections.Counter(nums)
ans = [num for num, occ in freq.items() if occ == 1][0]
return ans
# (来源力扣)分析:
freq = collections.Counter(nums):
为什么要collections.,不能直接 freq = Counter(nums)吗:当使用 collections 模块中的 Counter 类时,需要在代码中使用 collections.Counter 形式来调用。也可以直接导入 Counter 类,然后在代码中使用 Counter(nums)。例如:
from collections import Counter
freq = Counter(nums)以上两种方法都可以。
ans = [num for num, occ in freq.items() if occ == 1][0]:
for num, occ in freq.items(): 遍历freq.items()的可迭代对象,根据 if 后的条件将每个键(表示为num)和对应的值(表示为occ)分别赋值给迭代变量num。
if occ == 1:在迭代过程中对每个键值(即出现频率)对进行判断。当值等于1时,才把这个键添加到num中。
[0]: 返回列表中的第一个元素。
剑指 Offer 56 - I. 数组中数字出现的次数
https://leetcode.cn/problems/shu-zu-zhong-shu-zi-chu-xian-de-ci-shu-lcof/description/
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。
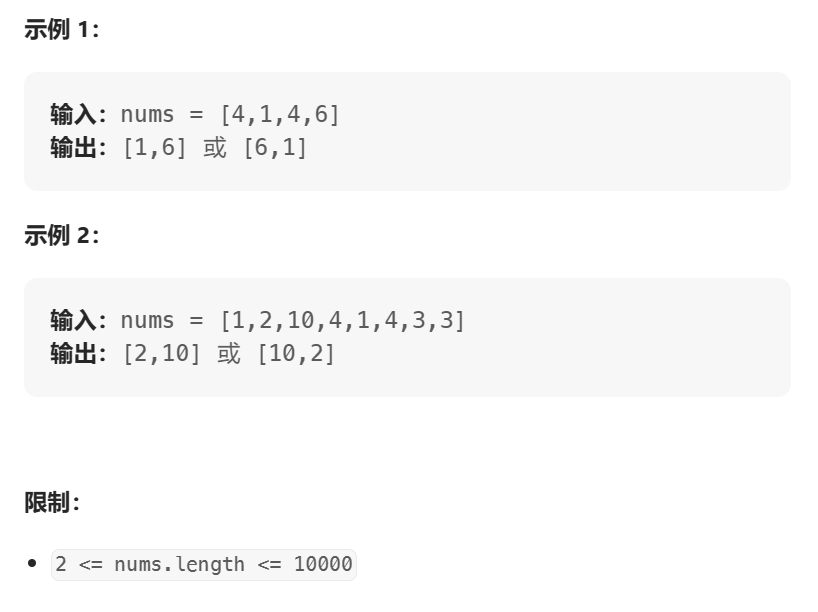
思路:
找出现频率1的数字。不止1个,用列表储存。用Counter()记录数字(key)与频率(value),用for遍历字典,找到value==1的值,用append添加在列表后。
题解:
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
cnt = Counter(nums)
res = list()
for key, value in cnt.items():
if value == 1:
res.append(key)
return res分析:
res.append(key):
将变量key的值添加到列表res的末尾。
res.append() = key是错误的语法,append()方法返回的是 None,而 = 操作符需要左侧是一个变量或表达式才能进行赋值操作。
剑指 Offer 03. 数组中重复的数字
https://leetcode.cn/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/description/
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。

题解:
class Solution:
def findRepeatNumber(self, nums: List[int]) -> int:
cnt = Counter(nums)
for key, value in cnt.items():
if value != 1:
return key 哈希表解法:
class Solution:
def findRepeatNumber(self, nums: [int]) -> int:
dic = set()
for num in nums:
if num in dic: return num
dic.add(num)
return -1
# (来源力扣)思路:
找重复数字,创建集合,用for把数字逐个加入集合,同时用if判断是否已经存在这个数。
剑指 Offer 50. 第一个只出现一次的字符
https://leetcode.cn/problems/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof/
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。

题解:
class Solution:
def firstUniqChar(self, s: str) -> str:
cnt = Counter(s)
for key, value in cnt.items():
if value == 1:
return key
break
return " " 分析:
break加不加都一样。
return " "不能return"",记得空格。
哈希表解法:
class Solution:
def firstUniqChar(self, s: str) -> str:
dic = {}
for c in s:
dic[c] = not c in dic
for c in s:
if dic[c]: return c
return ' '
# (来源力扣)有序哈希表:(效率更高)
class Solution:
def firstUniqChar(self, s: str) -> str:
dic = {}
for c in s:
dic[c] = not c in dic
for k, v in dic.items():
if v: return k
return ' '
(来源力扣)思路:
需要找出现频率为1的字符,创建字典遍历字符串,用布尔值记录之前是否已经出现过(需要否,否为True)。遍历字典,返回第一个True值的键,若不存在,返回‘ ’。
分析:
dic = {}:创建一个空字典dic用于保存字符和对应的出现次数。
dic[c] = not c in dic:
字典 dic 的键是变量 c。遍历字符串时,变量 c 会依次指向字符串中的每个字符。
not c in dic 会检查字符 c 是否存在于字典 dic 的键中。如果 c 存在于字典的键中,则 not c in dic 的结果为 False。如果 c 不存在于字典的键中,则 not c in dic 的结果为 True。
if v: return k:
如果值为True,表示该字符是第一个非重复字符,返回该字符。
692. 前K个高频单词
https://leetcode.cn/problems/top-k-frequent-words/
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。

思路:
按频率排序,Counter构造字典记录words和出现频率。sorted排序。返回前k个,切片[:k]
题解:
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
cnt = Counter(words)
return sorted(cnt, key=lambda x: (-cnt[x], x))[:k]分析:
Counter对象不能sort。
zip对象不能sort。想要对 zip 函数返回的结果进行排序,要先将其转化为一个列表,然后才能使用 sort 方法对列表进行排序。
zip 函数将多个可迭代对象中对应位置的元素打包成一个元组,并返回一个由这些元组组成的迭代器。例子:
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
zipped = zip(list1, list2)
for item in zipped:
print(item)
# Output:
# (1, 'a')
# (2, 'b')
# (3, 'c')return sorted(cnt, key=lambda x: (-cnt[x], x))[:k]:
使用 sorted 函数对 cnt 按照两个条件进行排序:首先 -cnt[x] 按照单词出现次数的降序排序,如果两个单词出现次数相等,则 x 按照单词本身的顺序排序。排序之后返回的中间结果是一个列表。(在这里根据代码的语义和上下文,可以判断 x 代表 cnt 字典中的键。)
切片操作 [:k],获取排序后的列表的前返回的中间结果是一个列表。 k 个元素,即出现频率最高的 k 个单词,并将其作为函数的返回值。
剑指 Offer II 034. 外星语言是否排序
https://leetcode.cn/problems/lwyVBB/
某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。
给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外星语中按字典序排列时,返回 true;否则,返回 false。

题解:
class Solution:
def isAlienSorted(self, words: List[str], order: str) -> bool:
index = {c: i for i, c in enumerate(order)}
return all(s <= t for s, t in pairwise([index[c] for c in word] for word in words))
# (来源力扣)分析:
index = {c: i for i, c in enumerate(order)}:
c: i for i, c in enumerate(order):遍历 enumerate(order) 返回的每个元素,元素→键,位序→值。
return all(s <= t for s, t in pairwise([index[c] for c in word] for word in words)):
pairwise :来自 itertools 模块,用于生成可迭代对象中相邻的元素对。这里它将每个单词中的相邻字母的索引位置组成的列表作为参数进行迭代。all 函数用于判断这些相邻索引组合是否满足条件,即前一个索引值小于等于后一个索引值。
(s <= t for s, t in pairwise(...)):遍历由相邻索引对组成的迭代对象。每个索引对 (s, t) 都会进行判断,生成一个布尔值,表示前一个索引值 s 是否小于等于后一个索引值 t。
all():接受一个可迭代对象,并检查其中的每个元素是否都为 True。如果所有元素都为 True,则返回 True;否则返回 False。