KNN(K-Nearest Neighbor k近邻算法):
一种基于实例的学习方法,或者是局部近似和将所有计算推迟到分类之后的惰性学习。
KNN用于分类和回归。它是所有的机器学习算法中最简单的之一。它通过在训练集中查找与测试样本最相似的k个邻居来进行预测。KNN本质是基于一种数据统计的方法。
思路:
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近。通常K是不大于20的整数。)的样本中的大多数属于某一个类别,则该样本也属于这个类别。即,该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
用于回归:
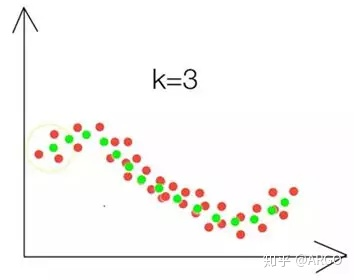
要预测的点的值通过求与它距离最近的K个点的值的平均值得到,这里的“距离最近”可以是欧氏距离,也可以是其他距离,具体的效果依数据而定,思路一样。如下图,x轴是一个特征,y是该特征得到的值,红色点是已知点,要预测第一个点的位置,则计算离它最近的三个点(黄色线框里的三个红点)的平均值,得出第一个绿色点,依次类推,就得到了绿色的线,可以看出,这样预测的值明显比直线准。
参考:
https://zhuanlan.zhihu.com/p/53084915
https://zhuanlan.zhihu.com/p/23191325#%E5%8A%9F%E8%83%BD%E8%AF%A6%E8%A7%A3