目录
前言
NeurIPS 2023,原文链接:arxiv.org/abs/2305.10665
论文源码:github.com/Omenzychen/Adversarial_Content_Attack.git
解决的问题
在 $l_p$ 范数下生成的对抗性例子有明显的局限性:1)在感知相似性方面不理想,易被人类感知;2)扰动不够自然,对抗性样本与现实世界中出现的真实样本不同。
因此,有了无限制的对抗性攻击,利用无限制但自然的变化来替代小的 $l_p$ 范数扰动。
作者认为理想的无限制攻击应该满足三个标准:i)它需要保持人类视觉上的不可察觉性和图像的真实感;ii)攻击内容应该是多样化的,允许不受限制地修改图像内容,如纹理和颜色,同时确保语义一致性;iii)对抗性样本应该具有高攻击性能,以便它们可以在不同模型之间传输。
本文介绍了一种名为Content-based Unrestricted Adversarial Attack的新型无限制对抗攻击框架。该框架通过利用代表自然图像的低维流形,将图像映射到流形上,并沿着其对抗方向进行优化,从而实现对抗内容攻击(ACA)。ACA基于稳定扩散,可以生成具有各种对抗内容的高可转移性的无限制对抗样本。大量实验和可视化展示了ACA的有效性,特别是在通常训练的模型和防御方法方面,超越了现有攻击方法平均13.3-50.4%和16.8-48.0%。
提出的方法
ACA(Adversarial Content Attack, 对抗内容攻击)流程图
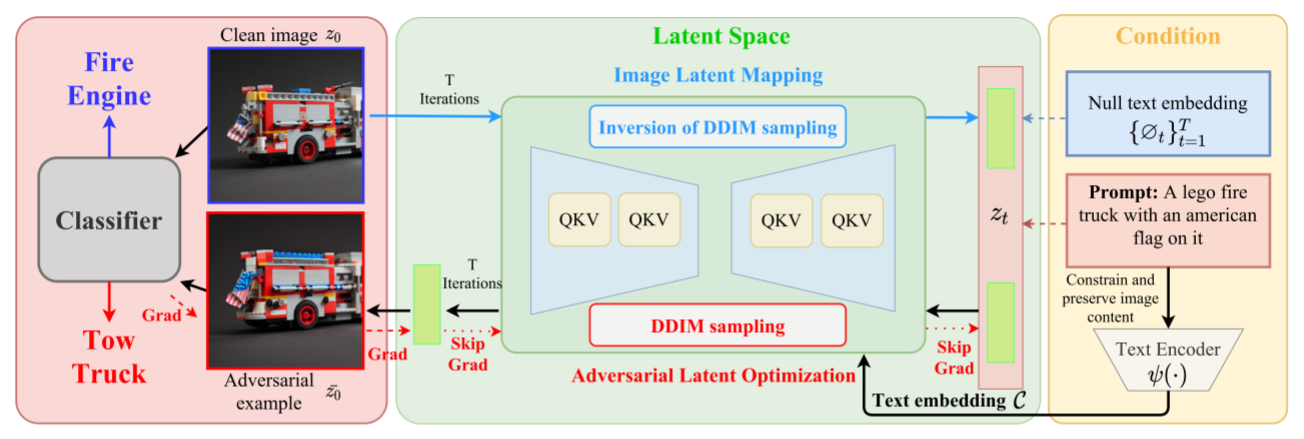
1.图像潜层映射(ILM):将图像映射到由低维流形表示的潜在空间。
2.对抗潜层优化(ALO):引入对抗潜在优化技术,沿着流形上的对抗方向移动图像的潜在表示。
3.迭代优化:通过迭代优化过程,生成高可转移的无限制对抗样本,使其外观非常自然。
ILM (Image Latent Mapping, 图像潜层映射)
名词解释
- VAE(Variational Autoencoder, 变分自动编码器):一种生成模型,结合了自动编码器(Autoencoder)和变分推断(Variational Inference)的思想,用于学习数据的潜在表示和生成新的数据样本。在ILM中,VAE可以被用于实现图像到潜在空间的映射和重构,为后续的对抗攻击步骤提供合适的输入和表示。
- DDIM (Denoising Diffusion Implicit Models, 去噪扩散隐式模型):一种用于生成高质量图像的生成模型,结合了去噪和扩散过程,具有出色的语义生成能力,能够生成符合提示语义的高质量自然图像。在ACA中,作者选择稳定扩散作为低维流形,用于生成逼真的自然图像。
方法简述
将图像映射到这个低维流形所表示的潜层空间上。
具体操作
对于扩散模型,最简单的图像映射方式是DDIM采样的逆过程。我们将有关prompts $P$ 的 $C = ψ(P)$ 嵌入公式,图像的映射过程表示为:
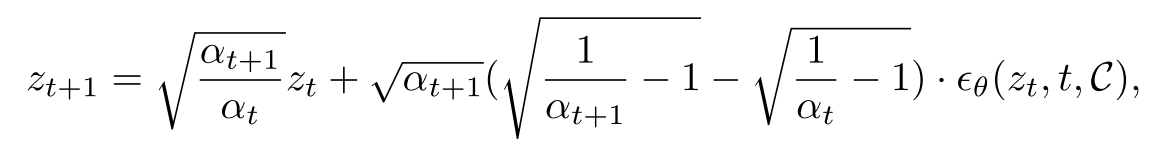
其中,$z_0$ 表示给定的干净图像,时间戳用${β_0, ..., β_T}∈(0, 1)$ 表示,且$α_t = Π_1^t(1-β_i)$,$α_t$ 表示在不同时间步骤的系数,可以控制每个时间步骤中的扩散强度。
prompts由图像描述模型(比如BLIP v2)来自动生成。这里简化了VAE编码步骤。作者使用无分类器制导技术(classifier-free guidance technique),给定 w 作为引导尺度参数,$∅ = ψ(””)$ 作为空文本的嵌入,无分类器引导预测表示为:
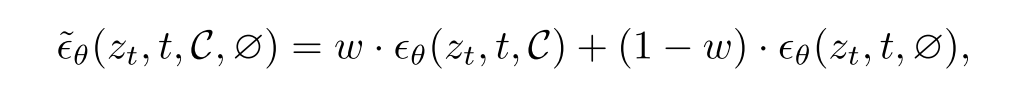
其中,$ϵ_θ(z_t, t, C)$ 表示在给定条件 $C$ 下生成的噪声项,$ ϵ_θ(z_t, t, ∅)$ 表示在无条件信息 $∅$ 下生成的噪声项。
由于噪声是由模型在DDIM采样的逆过程中预测的,因此每个步骤都包含一个轻微的误差。无分类器制导技术中存在系数w,这导致轻微的误差被放大并导致累积误差。因此,在无分类器的指导下执行DDIM采样的逆过程不仅会破坏噪声的高斯分布,还会诱发不现实的视觉伪影。
为了解决这个问题,作者follw了《Null-text inversion for editing real images using guided diffusion models》的方法。
ALO (Adversarial Latent Optimization, 对抗性潜层优化)
方法简述
在潜在空间中寻找对抗性扰动,实现对模型的干扰,生成具有高可转移性的对抗样本。
具体操作
在图像潜层映射后的潜空间中,空文本嵌入 $ ϵ_t$ 确保重构图像的质量,文本嵌入 $C$ 确保图像的语义信息。同时优化两个嵌入可能并不理想。考虑到噪声 $z_T^-$ 在很大程度上代表了图像在潜在空间中的信息,作者选择优化它。上一步中,扩散模型的去噪过程定义为:
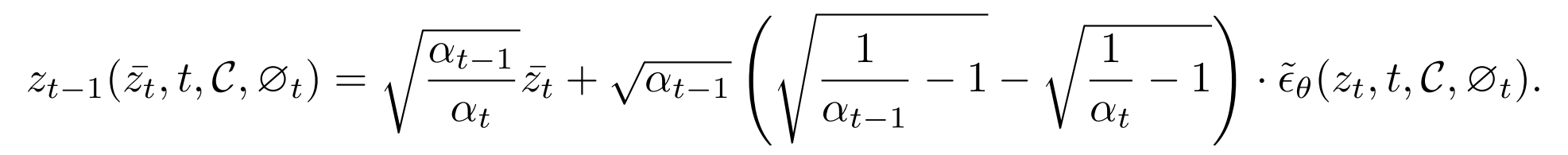
对抗优化目标函数表示为:
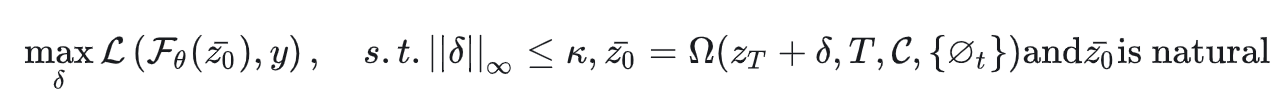
损失函数 $L$ 由交叉熵损失和均方误差损失组成: $L = Lce + βL{mse}$ ,为了确保 $z_0$ 和 $z0^-$ 的一致性,作者假设 $σ$ 极小的时候不会改变它们的一致性,( $i.e., ||σ||∞ ≤ k$ )。与传统对抗攻击一样,作者使用基于梯度的技术来估计 $σ$,$σ ≃ η ▽_{Z_T}L(F_θ(z_0^-), y)$ , $η$ 表示在梯度方向发生的扰动的大小。
接着,ALO采用跳跃梯度方法来确定去噪过程的梯度(因为一个完整的去噪过程在计算图中会导致内存溢出),并结合可微边界处理来限制对抗性样本的值范围(由于扩散模型没有明确限制 $z_0^-$ 的值范围,因此修改 $z_T$ 可能会导致超出值的范围)。最后根据梯度执行迭代优化。
ACA伪代码

实验结果可视化

优缺点
-
优点:
- 提出了一种新颖的无限制对抗攻击框架,利用高容量(模型处理大量或复杂性信息的能力)和对齐的低维流形生成更多样化和自然的对抗样本。
- 实现了Adversarial Content Attack (ACA),通过图像潜在映射和对抗潜在优化技术,在扩散模型中优化潜在表示,生成高迁移性的无限制对抗样本。相比现有攻击方法,平均提升了13.3-50.4%的对抗传递性。
-
缺点:
- 耗时长。